
Rapport technique sur l'échantillonnage et la pondération, Recensement de la population, 2021
6. Estimation de la variance
L’erreur d’une estimation est la différence entre l’estimation et la valeur réelle de ce que l’on vise à estimer. Toutes les estimations des questionnaires du recensement sont sujettes aux erreurs non dues à l’échantillonnage comme l’erreur de non‑réponse totale. Les estimations du questionnaire détaillé sont aussi sujettes à l’erreur d’échantillonnage. L’erreur d’échantillonnage provient du fait que les estimations sont produites à partir d’observations provenant d’un échantillon et non du Recensement de la population. L’erreur de non-réponse totale survient quand des ménages sélectionnés dans l’échantillon ne répondent pas à l’enquête.
L’erreur d’une estimation a une composante aléatoire, mesurée par la variance, et une composante systématique, mesurée par le biais. La variance mesure la variabilité de l’estimation par rapport à l’estimation moyenne qui résulterait de répétitions hypothétiques du processus d’enquête. Cette variance peut être estimée à partir des données de l’échantillon. Le biais est la différence entre la valeur moyenne d’une estimation qui résulterait de répétitions hypothétiques du processus d’enquête et la valeur réelle de la caractéristique estimée. Les méthodes d’échantillonnage et d’estimation utilisées dans l’enquête-échantillon du questionnaire détaillé visent toutes à réduire au minimum le biais.
Certaines méthodes d’estimation sont plus précises que d’autres pour estimer une caractéristique donnée de la population. Elles ont donc une incidence sur l’erreur. La variance estimée peut être utilisée pour produire plusieurs indicateurs de qualité couramment utilisés pour mesurer la précision d’une estimation. Par exemple, elle peut être utilisée pour calculer des erreurs-types, des intervalles de confiance et des coefficients de variation. L’intervalle de confiance a été choisi comme indicateur de la qualité fondé sur la variance pour appuyer les estimations du questionnaire détaillé du Recensement de la population de 2021 parce qu’il permet aux utilisateurs de réaliser facilement une inférence statistique. Par conséquent, les intervalles de confiance accompagnent généralement les estimations du questionnaire détaillé dans les produits de données du Recensement de 2021.
Il est important de bien distinguer ces mesures de variabilité des autres mesures de la qualité qui ne sont pas des mesures de variabilité proprement dites. Des exemples de telles mesures sont les taux de réponse finaux présentés à la section 3.11 et le taux d’imputation d’une réponse manquante. Pour obtenir de plus amples renseignements, veuillez consulter le chapitre 9 du Guide du Recensement de la population, 2021, produit no 98-304-X au catalogue de Statistique Canada, et les Lignes directrices sur la qualité des données du Recensement de 2021, produit no 98-26-0006 au catalogue de Statistique Canada.
Comme l’échantillon du questionnaire détaillé est stratifié géographiquement selon des strates à tirage partiel (les UC d’envoi par la poste, de listage/livraison et d’envoi par la poste et livraison à la porte) et des strates à tirage complet (les UC dans les communautés des Premières Nations, les établissements métis, les régions inuites et d’autres régions éloignées), deux estimateurs de variance sont utilisés. Un premier estimateur de variance est utilisé pour estimer la variance dans les aires géographiques à tirage partiel (voir la section 6.3.1) et un deuxième estimateur est utilisé pour estimer la variance due à la non‑réponse totale dans les aires à tirage complet (voir la section 6.3.2). Pour le reste du présent chapitre, le terme variance est employé pour désigner la variance d’échantillonnage et de non‑réponse totale dans les aires géographiques à tirage partiel ou la variance de non-réponse totale dans les aires à tirage complet.
6.1 Éléments à considérer pour choisir une méthode d’estimation de la variance
Un très grand nombre d’estimations diverses ont été produites, et des indicateurs de qualité pour ces mêmes estimations devaient être établis dans un délai raisonnable. Par conséquent, un estimateur de variance par rééchantillonnage, dérivé de la méthode modifiée par répliques répétées partiellement équilibrées, a été utilisé (Judkins, 1990). Cette méthode a été utilisée pour la première fois lors du Recensement de 2016 et a été largement maintenue pour le Recensement de 2021. La méthode consiste à tirer des échantillons (ou répliques) à partir de l’échantillon original. Des poids sont calculés pour chacune des répliques et ceux-ci subissent les mêmes ajustements de couverture, de non-réponse et de calage que l’échantillon original. Dorénavant, les poids établis à partir de l’échantillon original sont appelés poids principaux. Les poids résultant de chacune des répliques sont appelés poids de répliques. Des estimations sont ensuite produites pour chaque réplique, puis la variance est estimée à l’aide des estimations des répliques et des poids principaux.
La figure 6.1.1 donne un aperçu du concept d’estimation de la variance par répliques lorsque échantillons sont utilisés.
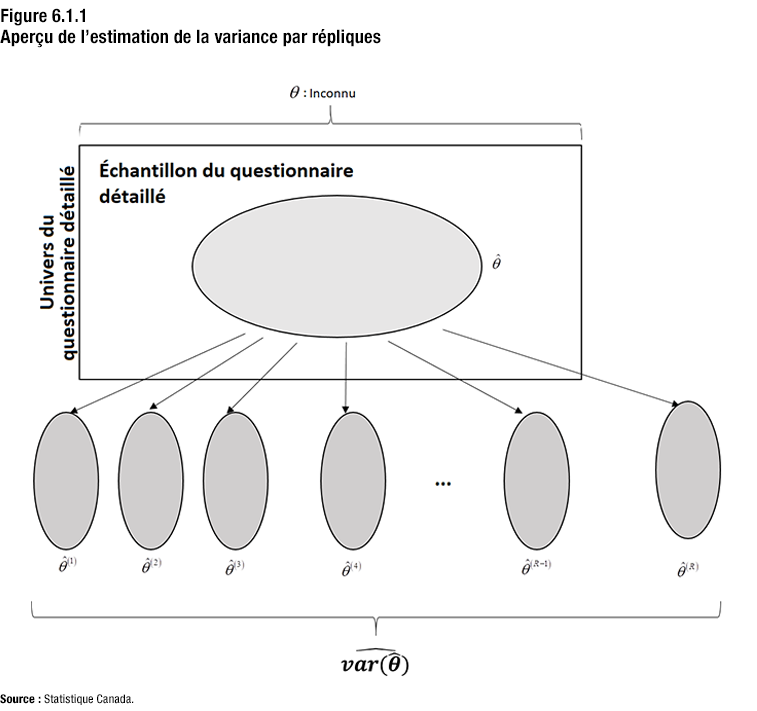
Description de la figure 6.1.1
En haut de la figure, on trouve une accolade horizontale indiquant que le paramètre de population thêta est inconnu.
Un encadré situé en dessous représente l’univers de l’échantillon du questionnaire détaillé.
Dans l’encadré se trouve un ovale qui représente l’échantillon du questionnaire détaillé tiré de cet univers. Thêta chapeau, un estimateur du paramètre de population de cet échantillon, est inscrit à côté de cet ovale.
Six lignes vont de cet ovale à six ovales plus petits situés à l’extérieur de l’encadré qui représentent les échantillons répétés utilisés pour l’estimation de la variance. Les quatre premiers sont séparés des deux derniers par trois points.
De gauche à droite, les ovales sont étiquetés de la façon suivante : thêta chapeau 1, thêta chapeau 2, thêta chapeau 3, thêta chapeau 4, thêta chapeau R-1 et thêta chapeau R.
Sous les ovales se trouve une accolade regroupant tous les ovales des échantillons répétés avec l’inscription valeur estimée de la variance de thêta chapeau, ce qui indique que la variance de l’estimateur d’échantillon est calculée au moyen des R estimations d’échantillons répétés.
Source : Statistique Canada.
Description complète :
La figure 6.1.1 donne un aperçu de la méthodologie d’estimation de la variance par répliques utilisée dans le cadre du Recensement de 2021. La méthode d’estimation de la variance par répliques simule la sélection de plusieurs échantillons afin d’estimer la variance d’échantillonnage.
Plus précisément, la figure montre l’univers du questionnaire détaillé qui représente la population d’intérêt ainsi que l’échantillon du questionnaire détaillé. L’échantillon est situé à l’intérieur de l’univers pour indiquer qu’il correspond à un sous-ensemble de la population d’intérêt. Cet échantillon permet d’estimer une caractéristique de la population d’intérêt, par exemple « le nombre de personnes faisant partie d’une minorité visible »Note 1. Le symbole thêta est utilisé pour représenter la valeur réelle de cette caractéristique. Un accent circonflexe sur le thêta indique que la valeur représente une estimation de cette caractéristique. Cette valeur est appelée thêta chapeau.
Les autres échantillons placés hors de l’univers sont reliés à l’échantillon du questionnaire détaillé par des flèches. Les flèches indiquent que ces échantillons sont tirés de l’échantillon du questionnaire détaillé. La caractéristique d’intérêt est réestimée à partir de ces sous-échantillons. Les valeurs de thêta chapeau, nommées thêta chapeau un, thêta chapeau deux, jusqu’à thêta chapeau sont utilisées pour calculer la variance estimée de thêta chapeau.
Nous définissons :
- thêta, , la valeur réelle de la caractéristique dans la population, qui peut être un total, une moyenne, un quantile, etc.;
- thêta chapeau, , la valeur de estimée à partir des poids principaux;
- thêta chapeau , , la valeur de estimée à partir des poids de la réplique , ;
- thêta chapeau barre, , la valeur moyenne des estimations de répliques ;
- , la valeur estimée de la variance de .
6.2 Estimateur de variance
L’estimateur par répliques choisi pour l’enquête-échantillon du questionnaire détaillé a été dérivé de la méthode des demi-échantillons équilibrés de Fay (Judkins, 1990). La méthode détermine la création des répliques, le calcul des poids de répliques ainsi que le facteur multiplicatif utilisé pour estimer la variance.
Afin de produire les estimations de variance des estimations de l’échantillon du questionnaire détaillé, deux ensembles de poids de répliques ont été créés : un premier ensemble pour 32 poids de répliques et un deuxième ensemble pour 100 poids de répliques. L’ensemble de 32 poids de répliques a été produit pour estimer les erreurs-types de produits normalisés dont le calcul est sujet à des contraintes opérationnelles (c.-à-d. le besoin de diffuser un grand nombre d’intervalles de confiance dans un délai raisonnable). L’ensemble de 100 poids de répliques a été mis à la disposition des analystes de Statistique Canada et des analystes des centres de données de recherche qui ont accès aux microdonnées, et ce, afin de leur fournir des estimateurs de variance plus précis.
L’estimateur de variance par répliques peut être calculé de deux façons, dont une plus conservatrice que l’autre. La première méthode consiste à additionner les différences au carré entre les estimations de répliques, , et la moyenne des estimations des répliques, . La seconde méthode consiste à additionner les différences au carré entre les estimations des répliques, , et l’estimation provenant de l’échantillon principal, . Pour les deux méthodes, la somme des différences au carré est multipliée par un certain facteur. La deuxième méthode, qui utilise l’estimation provenant de l’échantillon principal, est plus conservatrice. Dans le système informatique utilisé pour la diffusion de statistiques, l’estimateur de variance est calculé à partir de l’estimation provenant de l’échantillon principal.
Par exemple, deux estimateurs de variance pour un estimateur d’un total calculé à partir d’un ensemble de répliques sont donnés par les équations suivantes :
,
où
,
, et
.
Le poids final de l’échantillon est représenté par , est le poids final de la réplique , est la valeur de la caractéristique pour l’unité et est l’échantillon du questionnaire détaillé.
Le nombre de degrés de liberté de l’estimateur de variance est approximé par le nombre de différences au carré , soit 32 ou 100, de l’estimateur de variance. Le nombre de degrés de liberté donne un aperçu de la précision de l’estimateur de variance et il est utilisé lors du calcul d’intervalles de confiance pour les estimations provenant du questionnaire détaillé. Voir le chapitre 7 pour obtenir plus de détails.
6.3 Ajustement des poids de répliques
6.3.1 Unités de collecte d’envoi par la poste et de listage/livraison
Comme mentionné à la section 6.2, les poids de répliques ont été calculés pour tous les ménages de l’échantillon du questionnaire détaillé. Les répliques ont été partiellement équilibrées. Elles ont été équilibrées par strate de rééchantillonnage, celles-ci étant créées en combinant des UC de façon à obtenir de 600 à 1 800 ménages par strate de rééchantillonnage.
La méthode modifiée des demi-échantillons équilibrés de Fay, décrite par Rao et Shao (1999), exige une valeur « epsilon » dans le calcul des poids de répliques afin de contrôler la perturbation des poids de répliques. Cette perturbation fait en sorte que tous les ménages échantillonnés participent à chacune des répliques, contrairement à d’autres méthodes d’estimation par répliques plus courantes. Cela facilite le calage des poids de répliques et, à l’occasion, le calcul des estimations ponctuelles sur chacune des répliques (p. ex. le dénominateur d’un estimateur de ratio pour une réplique donnée ne sera pas nul si le dénominateur correspondant n’était pas nul avec le poids final). L’ajout d’un facteur epsilon dans le calcul des poids de répliques a aussi permis de tenir compte de la grande fraction de sondage utilisée pour sélectionner l’échantillon du questionnaire détaillé. Les détails techniques relatifs au processus de l’estimation de la variance sont donnés dans Devin et Verret (2016).
Les poids de répliques ont été assujettis aux mêmes ajustements que le poids de sondage de l’échantillon principal. Ils ont été ajustés pour la couverture et la non-réponse totale en suivant la même méthodologie que pour le poids de l’échantillon principal (voir la section 4.4). Ensuite, les poids de répliques résultants ont été calés aux chiffres du recensement, toujours en suivant la même méthodologie que pour le poids principal (voir la section 4.5).
6.3.2 Unités de collecte dans les communautés des Premières Nations, les établissements métis, les régions inuites et d’autres régions éloignéesNote 2
Comme le décrit le chapitre 2, tous les ménages situés dans des UC dans les communautés des Premières Nations, les établissements métis, les régions inuites et d’autres régions éloignées ont été sélectionnés avec certitude. Par conséquent, ils avaient à l’origine un poids de sondage de 1. Aucun ajustement pour la couverture n’était nécessaire. Tous ces ménages ont été sélectionnés pour le questionnaire détaillé; il ne pouvait donc pas y avoir de différence de couverture entre le questionnaire abrégé et le questionnaire détaillé. La non-réponse totale dans ces aires a été traitée par le processus d’imputation des ménages entiers, décrit au chapitre 3. En d’autres mots, les données d’un ménage non répondant ont été remplacées par les données d’un ménage répondant de la même UC (à l’exception des variables géographiques des non-répondants, que l’on connaissait déjà). La repondération n’a donc pas été nécessaire pour les ménages situés dans ces UC.
Le calage n’a pas non plus été nécessaire pour ces aires, car le questionnaire détaillé était un recensement. Par conséquent, tous les ménages situés dans les UC dans les communautés des Premières Nations, les établissements métis, les régions inuites et d’autres régions éloignées ont conservé leur poids original de 1 dans le plan de pondération final.
Bien qu’il n’y ait pas eu de variabilité d’échantillonnage dans les ménages situés dans les UC dans les communautés des Premières Nations, les établissements métis, les régions inuites et d’autres régions éloignées, il y a eu de la variabilité liée à l’imputation des ménages entiers. L’estimation de la variance dans ces aires a été calculée selon une méthode semblable à celle pour le reste du pays, à quelques exceptions près. Premièrement, la probabilité de réponse selon la combinaison de la taille du ménage dans chaque division de recensement a été estimée en divisant le nombre de ménages répondants par le nombre de ménages dans le champ de l’enquête. Ensuite, les poids de répliques de base ont été créés comme pour le reste du pays, à l’exception du fait que tous les répondants dont la probabilité de réponse était égale à 1 ont été placés dans chaque réplique. Les répondants dont la probabilité de réponse estimée était inférieure à 1 n’ont pas été considérés comme des certitudes et ont été traités comme des éléments échantillonnés (c.-à-d. qu’ils ont été répartis aléatoirement entre les répliques). Les ménages non répondants imputés par l’imputation des ménages entiers ont également été répartis entre les répliques, et chacun s’est vu attribuer l’indicateur d’inclusion dans la réplique correspondant à son donneur d’une manière semblable à celle de Shao et Tang (2011). Ainsi, les poids ont varié d’une réplique à l’autre. Enfin, les poids de répliques ont été calés en fonction du nombre de ménages et du nombre de personnes dans la SADA. Par conséquent, la variance estimée de ces deux quantités était égale à 0 au niveau de la SADA et aux niveaux plus agrégés, par exemple au niveau du Canada (puisque ces deux contraintes sont obligatoires dans le reste du pays).
- Date de modification :