
Rapport technique sur la couverture, Recensement de la population, 2016
8. Étude sur le surdénombrement du recensement (ESR)
8.1 Aperçu et méthodologie
Avant 2006, le niveau de surdénombrement causé par le dédoublement des individus au recensement a été mesuré par trois études, chacune couvrant une partie du surdénombrement : l’Étude par appariement automatisé (EAA), l’Étude sur les logements collectifs (ELC) et la Contre-vérification des dossiers (CVD). Depuis 2006, les prénoms et noms ont été inclus à la base de données des réponses au recensementNote 1 et le surdénombrement est désormais mesuré par une simple étude : l’étude sur le surdénombrement du recensement (ESR). Ainsi, la CVD n’est plus utilisée pour mesurer le surdénombrement et l'ELC a été abandonnée. L’EAA est toujours menée à des fins d’évaluation.
Comme c’était le cas pour les deux études sur le surdénombrement de 2006 et 2011, l’ESR de 2016 s’est basée sur une série d’opérations de couplage d’enregistrements probabiliste et de vérifications manuelles de paires de cas potentiels de surdénombrement. Ces opérations de couplage d’enregistrements nécessitaient également l’utilisation de certains fichiers de données administratives.
Pour alléger la lecture du reste de cette section, une paire de cas potentiels de surdénombrement est appelée une paire et une paire confirmée comme étant la même personne est appelée un doublon.
L’ESR de 2016 est une étude statistique dans le cadre de laquelle le surdénombrement a été estimé au moyen d’un échantillon probabiliste tiré d’une base de sondage des cas potentiels de surdénombrement. L’ESR fait intervenir toutes les étapes existant dans une étude statistique :
- construction d’une base de sondage;
- sélection de l’échantillon;
- collecte des données;
- traitement et vérification des données recueillies;
- pondération et estimation;
- analyse.
Cependant, l’ESR diffère d’une enquête statistique pour les raisons suivantes :
- la base de sondage est construite au moyen d’opérations successives de couplage probabiliste et déterministe d’enregistrements;
- la collecte est fondée sur la vérification manuelle des paires d’enregistrements échantillonnées et ne fait pas intervenir de répondants.
La méthodologie de l’ESR pour estimer le surdénombrement de 2016 s’est basée sur l’appariement de personnes sans restrictions géographiques, alors que l’EAANote 2 s’est basée sur l’appariement de ménages privés situés dans la même région géographique. L’ESR de 2016 a utilisé fait que la Base de données des réponses du Recensement (BDR) de 2016 contenait les noms et prénoms des répondants sous forme de deux variables distinctes. Cela a permis de produire une estimation plus précise du surdénombrement dû à des personnes dénombrées plusieurs fois dans la base de données du recensement. L’ESR a eu recours à des méthodes d’appariement automatisées et de vérification manuelle. Elle a inclus les personnes vivant dans des logements collectifs et n’imposait pas de restrictions géographiques comme celles de l’EAA.
La base de données de recensement utilisée pour l’ESR était la même que celle utilisée pour la CVD : la BDR-ECR. Par souci de simplicité, on appelle ici cette dernière la BDR.
Comme en 2006 et en 2011, la base de sondage de l’ESR de 2016 a été créée en plusieurs étapes. La première étape a été un couplage d’enregistrements probabiliste interne dans le cadre duquel toute la BDR a été couplée à elle-même. La deuxième étape a été un couplage d’enregistrements probabiliste interne dans le cadre duquel toute la BDR a été couplée à une base de sondage administrative (ADMIN) créée à partir de la Base statistique de données démographiques canadiennes (BSDDC). La BSDDC est une base de données administratives créée à partir de multiples sources de données administratives utilisées dans le cadre du programme du recensement.
Ces deux couplages d’enregistrements probabilistes ont été effectués avec G-Coup 3.2, le système de couplage d’enregistrements probabiliste conçu à Statistique Canada utilisant la méthodologie Fellegi-Sunter pour résoudre des problèmes de couplage de fichiers volumineux lorsqu’aucun identificateur direct n’est commun aux deux sources (Fellegi et Sunter 1969).
8.2 Création de la base de sondage
L’ESR commence par la création d’une base de sondage des cas potentiels de surdénombrement à l’aide d’un couplage probabiliste et déterministe d’enregistrements. Ce travail comprend les quatre phases suivantes :
- un couplage d’enregistrements probabiliste entre la BDR et elle-même;
- un couplage d’enregistrements probabiliste entre la BDR et l’ADMIN;
- l’extension de la base de sondage fondée sur les ménages;
- Un supplément de base de sondage : un surdénombrement potentiel supplémentaire relevé au cours de l’évaluation du prototype de la BSDDC.
8.2.1 Fichiers en entrée pour la création de la base de sondage de l’ESR
La BDR contenait un peu moins de 34 millions d’enregistrements et comprenait les réponses des personnes vivant dans des logements privés et collectifs. Elle contenait les noms (y compris les prénoms et noms de famille), des données démographiques (y compris la date de naissance et le sexe) et des données géographiques (y compris la province ou le territoire et le code postal). L’ADMIN, extraite de la BSDDC, contenait plus de 48 millions d’enregistrements. Comme en 2011, l’ADMIN incluait les noms (prénoms et noms de famille), des données démographiques (y compris la date de naissance et le sexe) et des données géographiques (y compris la province ou le territoire et le code postal).
La BSDDC de laquelle l’ADMIN a été tirée a été créée à partir de multiples fichiers de données administratives. Ces derniers comprenaient des fichiers de données fiscales fournis par l’Agence du revenu du Canada, des fichiers relatifs aux immigrants permanents et aux résidents non permanents fournis par Immigration, Réfugiés et Citoyenneté Canada, des enregistrements de naissance de fichiers de statistiques de l’état civil fournis par la Statistique de l’état civil, le Système national d’acheminement ainsi que le Registre des Indiens fourni par Affaires autochtones et du Nord Canada.
Les enregistrements des personnes classées comme vivant dans l’un des trois territoires selon la BSDDC ont été remplacés par les données de fichiers sur les soins de santé territoriaux utilisés comme base de sondage pour la CVD, car on a pensé qu’ils fournissaient une meilleure couverture des personnes vivant dans les territoires.
Les variables d’appariement suivantes ont été utilisées dans les deux couplages BDR-BDR et BDR-ADMIN :
- noms : variables de prénoms et de noms de famille;
- données démographiques : variables de dates de naissance et de sexe;
- données géographiques : variables de province ou territoire et code postal.
8.2.2 Étapes de création de la base de sondage de l’ESR
La base de sondage de l’ESR comprenait toutes les paires formant les cas de surdénombrement potentiel produits par G-Coup à la suite des étapes 1 et 2 et ceux relevés par l’extension. Elle incluait également les paires d’enregistrements relevées par le supplément. La création de la base de sondage de l’ESR est illustrée à la figure 8.2.2 ci-dessous :
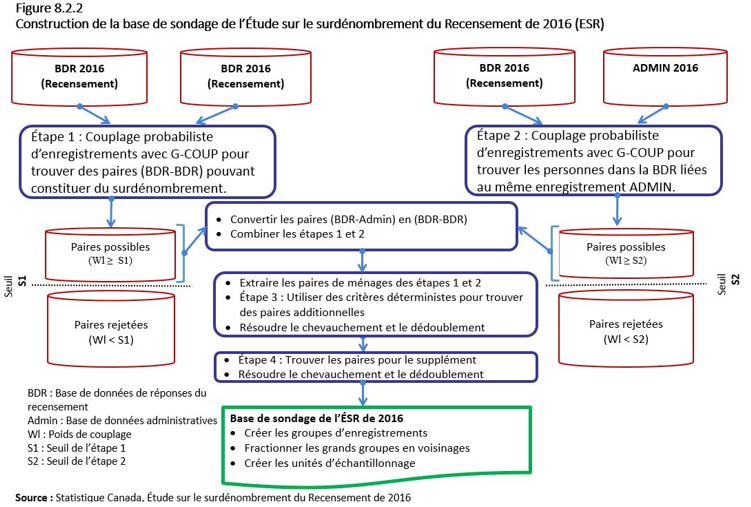
Description de la figure 8.2.2
La figure 8.2.2 s’intitule « Construction de la base de sondage de l’Étude sur le surdénombrement du Recensement de 2016 (ESR) ».
La première case de la figure comporte l’étape 1 : Couplage probabiliste d’enregistrements avec G-Coup pour trouver des paires (BDR-BDR) (c.-à-d. les paires dans la base de données des réponses [BDR] du Recensement de 2016) pouvant constituer un surdénombrement.
Cette case mène à deux types de paires : les paires possibles (poids de couplage supérieur ou égal au seuil de l’étape 1) et les paires rejetées (poids de couplage inférieur au seuil de l’étape 1).
Les paires possibles figurent au-dessus du seuil de l’étape 1.
Du côté droit de la figure se trouve la case de l’étape 2 : Couplage probabiliste d’enregistrements avec G-Coup pour trouver les personnes dans la BDR liées au même enregistrement dans la base de données administratives (ADMIN).
Cette case mène à deux types de paires : les paires possibles (poids de couplage supérieur ou égal au seuil de l’étape 2) et les paires rejetées (poids de couplage inférieur au seuil de l’étape 2).
Les paires possibles figurent au-dessus du seuil de l’étape 2.
La case du côté gauche qui contient les paires possibles de l’étape 1 et celle du côté droit qui contient les paires possibles de l’étape 2 mènent à la prochaine case. Cette dernière se trouve au milieu de la figure et comporte une liste à deux puces :
- Convertir les paires BDR-ADMIN en paires BDR-BDR
- Combiner les étapes 1 et 2
Une flèche mène à la case d’en dessous, qui comporte une liste à trois puces :
- Extraire les paires de ménages des étapes 1 et 2
- Étape 3 : Utiliser des critères déterministes pour trouver des paires additionnelles
- Résoudre le chevauchement et le dédoublement
En dessous de cette case se trouve une autre case, qui comporte une liste à deux puces :
- Étape 4 : Trouver les paires pour le supplément
- Résoudre le chevauchement et le dédoublement
En dessous de cette case se trouve une flèche qui mène à la dernière case : Base de sondage de l’ESR de 2016. Cette case comporte une liste à trois puces :
- Créer les groupes d’enregistrements
- Fractionner les grands groupes en voisinages
- Créer les unités d’échantillonnage
Source : Statistique Canada, Étude sur le surdénombrement du Recensement de 2016
8.2.3 Étape 1 : couplage probabiliste BDR-BDR
L’objectif de l’étape 1 était de mesurer le surdénombrement des personnes dans la BDR. Pour optimiser le couplage d’enregistrements, des catégories de fréquence de nom provinciales et territoriales ont été créées afin de comparer les prénoms et les noms de famille. On a utilisé les catégories de fréquence comme niveaux de résultats dans les règles de concordance de noms dans G-Coup 3.2.
Ce processus d’appariement se basait sur la série d’opérations suivantes :
- création de paires d’enregistrements BDR-BDR potentielles en appliquant des critères de sélection;
- calcul des fréquences de noms (pour les noms de famille et les prénoms) au sein de chaque province et territoire;
- création des catégories de fréquence de noms;
- comparaison des enregistrements pour les paires potentielles en appliquant des règles de concordance;
- calcul des poids des résultats de l’application des règles, au moyen de l’algorithme EM;
- établissement de seuils provinciaux et territoriaux;
- sélection de paires dont le poids était supérieur aux seuils.
De l’étape 1, un ensemble couplé de 4 254 360 paires potentielles a été créé.
8.2.4 Étape 2 : couplage probabiliste BDR-ADMIN
L’objectif de l’étape 2 était de relever le surdénombrement potentiel supplémentaire non capturé par le couplage de l’étape 1. Des paires d’enregistrements de la BDR ont été créées à partir de groupes de multiples enregistrements de la BDR couplés aux mêmes enregistrements d’ADMIN. Ce processus d’appariement a déterminé des paires pour lesquelles des erreurs de nom ou de date de naissance étaient telles que le couplage BDR-BDR ne pouvait pas les apparier lors d’une comparaison directe. Il a également permis de repérer les pseudo-doublons, c.-à-d. des enregistrements de la BDR et de l’ADMIN concordant pour de nombreuses variables d’appariement avec un poids d’appariement élevé, mais qui, en réalité, représentaient des personnes différentes. On a par conséquent procédé à un nettoyage des paires BDR-BDR dérivées des paires BDR-ADMIN.
La deuxième étape consistait en la séquence d’opérations suivante :
- création de paires potentielles BDR-ADMIN en appliquant des critères de sélection;
- calcul des fréquences de noms au sein de chaque province et territoire;
- création des catégories de fréquence de noms;
- comparaison des enregistrements pour les paires potentielles en appliquant des règles de concordance;
- calcul des poids des résultats de l’application des règles, au moyen de l’algorithme EM;
- établissement de seuils provinciaux et territoriaux;
- sélection de paires dont le poids était supérieur au seuil;
- création de paires BDR-BDR à partir de l’ensemble de paires BDR-ADMIN supérieures aux seuils;
- suppression des paires déjà relevées par le couplage de la première étape;
- vérification et nettoyage des paires BDR-BDR dérivées des paires BDR-ADMIN pour réduire les pseudo-doublons.
Le couplage BDR-ADMIN a relevé 930 120 paires supplémentaires qui ont été ajoutées à l’ensemble de paires potentielles.
8.2.5 Étape 3 : extension de la base de sondage fondée sur les ménages
L’extension de la base de sondage a pour objectif de relever un surdénombrement supplémentaire au sein des ménages présentant des cas potentiels de surdénombrement provenant des étapes 1 ou 2. Cette phase a entraîné la création de paires d’enregistrements BDR-BDR supplémentaires, produites en deux étapes.
Premièrement, une paire de ménages a été produite pour chaque paire de personnes BDR-BDR créée à l’étape 1 ou 2 en y ajoutant les autres membres du ménage. Ensuite, à l’aide des variables de sexe et de date de naissance, de nouvelles paires BDR-BDR ont été relevées en comparant les personnes présentes dans la paire de ménages. Des règles de comparaison ont été appliquées pour relever les paires pouvant représenter des cas de surdénombrement. L’extension de base de sondage comprenait des paires de deux ménages privés ou des paires au sein desquelles une personne d’un ménage privé était couplée à une personne d’un logement collectif. On a exclu les paires pour lesquelles les deux enregistrements provenaient de logements collectifs.
Comme pour les paires BDR-ADMIN, les paires déjà relevées aux deux premières étapes ont été supprimées. Une fois les doublons supprimés, la base de sondage d’extension a capturé 167 980 autres paires, qui ont été ajoutées à l’ensemble de paires potentielles.
8.2.6 Création des unités d’échantillonnage
Les cas potentiels de surdénombrement ont été repérés au moyen de groupes d’enregistrements interreliés de la BDR. Les paires de personnes BDR-BDR obtenues aux étapes 1 et 2 et l’extension ont été regroupées. Des groupes d’enregistrements mutuellement exclusifs ont été créés à partir de l’ensemble de paires de personnes non dupliquées; ce qui signifie qu’un groupe d’enregistrements contenait tous les enregistrements de la BDR reliés par un surdénombrement potentiel, comme le déterminent les étapes 1 à 3. Pour les cas où des groupes d’enregistrements contenaient plus de 10 enregistrements de la BDR, une méthode de théorie des graphes a été appliquée pour réduire le groupe en petits sous-groupes appelés « voisinages », afin de faciliter la vérification manuelle.
8.2.7 Étape 4 : Supplément à la base de sondage
Au cours de l’évaluation du prototype de la BSDDC de 2016, l’équipe de la BSDDC a relevé d’éventuels doublons avec la BDR. Cette liste d’éventuels doublons a été comparée à la base de sondage de l’ESR créée aux étapes 1 à 3. La plupart des potentielles paires relevées par l’équipe de la BSDDC avaient été capturées au cours des trois premières étapes décrites ci-dessus. Cependant, certaines de ces paires manquaient de l’ensemble de paires potentielles créé au cours des trois premières étapes. Une enquête sur les paires manquantes a révélé quelques paires supplémentaires non relevées par l’équipe de la BSDDC qui auraient dû être incluses à l’ensemble de paires potentielles. Un total de 97 000 paires ont été recensées de cette façon et ont été ajoutées à la base de sondage de l’ESR.
La base de sondage finale de l’ESR contenait un peu plus de 3,6 millions d’unités d’échantillonnage, créées à partir d’environ 5,4 millions de paires BDR-BDR.
8.3 Plan de sondage de l’ESR
Pour les besoins de l’échantillonnage, les unités de la base de sondage ont été séparées en quatre strates :
- Strate 1 : Il s’agit des unités intraprovinciales des étapes 1 à 3. Ce sont les unités d’échantillonnage créées lors des étapes 1 à 3 dont tous les enregistrements de la BDR formant les paires contenues dans l’unité se trouvent dans la même province ou le même territoire.
- Strate 2 : Il s’agit des paires interprovinciales des étapes 1 à 3. Ce sont les unités d’échantillonnage créées lors des étapes 1 à 3 et formées d’une seule paire d’enregistrement provenant de deux provinces ou territoires différents.
- Strate 3 : Il s’agit des groupes et voisinages interprovinciaux des étapes 1 à 3. Ce sont les unités d’échantillonnage créées lors des étapes 1 à 3 et formées d’au moins deux paires d’enregistrements, couvrant au moins deux provinces ou territoires. Il est à noter qu’une telle unité pouvait contenir des paires intraprovinciales. Par exemple, un groupe pouvait être composé de trois paires reliant des enregistrements de la BDR en Ontario, et d’une autre paire reliant un enregistrement de l’Ontario avec un autre de l’Alberta.
- Strate 4 : Il s’agit des paires de l’étape 4. Ce sont les paires de doublons potentiels déterminées par le supplément. Cette strate incluait à la fois des paires intraprovinciales et interprovinciales.
8.3.1 Répartition de l’échantillon
Le budget de vérification manuelle de l’ESR 2016 a été basé sur une taille d’échantillon totale semblable à celle utilisée en 2011, c’est-à-dire un échantillon de 54 000 paires à vérifier au total pour les strates 1 à 3. Il a été décidé qu’en moyenne, 70 % de l’échantillon d’une province serait constitué de paires intraprovinciales, et que le reste serait formé de paires interprovinciales. Cela représente une diminution de la proportion de paires intraprovinciales dans l’échantillon (qui était d’environ 80 % en 2011), étant donné que la base de 2016 contient davantage de paires interprovinciales.
L’échantillon de paires a été réparti entre les provinces et territoires à l’aide d’une méthode de répartition de puissance en prenant comme taille le nombre total de paires dans la base pour chaque province ou territoire, et comme puissance x = 0,2. Cela permettait d’obtenir des estimations précises pour chaque province ainsi qu’à l’échelle nationale, tout en permettant une distribution d’échantillon qui ne s’éloignait pas trop de celle de 2011. L’étape suivante consistait à répartir l’échantillon provincial et territorial entre les paires intraprovinciales et interprovinciales. Comme mentionné, la proportion globale visée était de 70 % de paires intraprovinciales. Une proportion plus faible a été utilisée pour l’Île-du-Prince-Édouard et les trois territoires, puisque les résultats de 2011 montrent que la contribution du surdénombrement interprovincial y était plus grande. À l’inverse, une proportion plus élevée a été utilisée pour le Québec, l’Ontario et la Colombie-Britannique. Une même proportion a ensuite été utilisée dans les autres provinces et a été fixée de façon à obtenir la proportion nationale de 70 %.
Une fois la taille de l’échantillon de paires intraprovinciales et interprovinciales déterminée pour chaque province et territoire, la prochaine étape consistait à répartir ces échantillons entre les trois strates. L’échantillon de paires interprovinciales a été séparé entre les strates 2 et 3 en fonction de la proportion de paires interprovinciales de la base dans chacune des deux strates. Pour ce qui est de la répartition de l’échantillon de paires intraprovinciales entre les strates 1 et 3, il n’était pas possible de procéder de la même manière. En effet, dans la strate 3, les groupes et voisinages étaient composés majoritairement de paires interprovinciales. Sélectionner le nombre voulu de paires intraprovinciales aurait alors entraîné la sélection de beaucoup trop de paires interprovinciales. Pour éviter ce problème, des simulations ont montré qu’il fallait sélectionner 85 % de l’échantillon de paires intraprovinciales à partir de la strate 1, afin que l’échantillon de la strate 3 soit réalisable. Pour l’Île-du-Prince-Édouard et les trois territoires, cela équivalait pratiquement à un tirage complet. Toutes les paires de la base dans la strate 1 y ont donc été sélectionnées.
Pour ce qui est de la strate 4, la taille de l’échantillon a été établie à 3 000 paires, en fonction du niveau de précision souhaitable, des ressources disponibles et des échéanciers à respecter au moment où les paires de la base du supplément ont été déterminées.
8.3.2 Échantillon de la strate 1
La strate 1 a été séparée en trois sous-strates à l’intérieur de chaque province: les paires, les groupes et les voisinages. Une répartition optimale de l’échantillon basée sur les coûts de vérification manuelle a été utilisée pour répartir l’échantillon provincial de cette strate aux sous-strates. Un échantillon systématique de paires triées par classe de poids de couplage, groupe d’âge, sexe, état matrimonial, langue maternelle et RMR a ensuite été sélectionné. Pour les groupes et les voisinages, un échantillon aléatoire simple a été sélectionné. Le tableau 8.3.2 fournit la distribution des unités d’échantillonnage de la strate 1 dans la base de sondage et dans l’échantillon, et ce, pour chaque sous-strate de chaque province et territoire.
| Provinces et territoires | Totaux sur la base | Totaux dans l’échantillon | ||||||
|---|---|---|---|---|---|---|---|---|
| Paires | Groupes | Voisinages | Total | Paires | Groupes | Voisinages | Total | |
| Canada | 1 165 224 | 192 530 | 172 610 | 1 530 364 | 30 481 | 1 702 | 1 420 | 33 603 |
| Terre-Neuve-et-Labrador | 9 133 | 296 | 159 | 9 588 | 2 386 | 96 | 74 | 2 556 |
| Île-du-Prince-Édouard | 1 763 | 42 | 20 | 1 825 | 1 763 | 42 | 20 | 1 825 |
| Nouvelle-Écosse | 14 328 | 626 | 368 | 15 322 | 2 644 | 137 | 82 | 2 863 |
| Nouveau-Brunswick | 13 844 | 591 | 309 | 14 744 | 2 604 | 129 | 60 | 2 793 |
| Québec | 413 625 | 102 703 | 76 085 | 592 413 | 3 284 | 416 | 308 | 4 008 |
| Ontario | 479 444 | 71 845 | 82 517 | 633 806 | 3 947 | 295 | 392 | 4 634 |
| Manitoba | 18 440 | 835 | 512 | 19 787 | 2 724 | 107 | 76 | 2 907 |
| Saskatchewan | 17 175 | 833 | 415 | 18 423 | 2 532 | 118 | 53 | 2 703 |
| Alberta | 75 638 | 4 261 | 3 448 | 83 347 | 3 445 | 126 | 118 | 3 689 |
| Colombie-Britannique | 120 458 | 10 460 | 8 775 | 139 693 | 3 776 | 198 | 235 | 4 209 |
| Yukon | 570 | 16 | 2 | 588 | 570 | 16 | 2 | 588 |
| Territoires du Nord-Ouest | 345 | 8 | 0 | 353 | 345 | 8 | 0 | 353 |
| Nunavut | 461 | 14 | 0 | 475 | 461 | 14 | 0 | 475 |
| Source : Statistique Canada, Étude sur le surdénombrement du Recensement de 2016. | ||||||||
8.3.3 Échantillon de la strate 2
Les unités d’échantillonnage de la strate 2 étaient toutes des paires interprovinciales. La strate 2 a donc été sous-divisée en fonction de la province des deux enregistrements BDR-ECR de la paire. Les paires d’une combinaison province 1 et province 2 ont ensuite été triées selon les mêmes variables utilisées dans la strate 1, et un échantillon systématique a été sélectionné. Le tableau 8.3.3 fournit la distribution des unités d’échantillonnage de la strate 2 dans la base de sondage et dans l’échantillon, pour chaque province et territoire. Il faut noter que puisque chaque paire appartient à deux provinces différentes, la somme du nombre de paires dans chaque province et territoire correspond au double du nombre de paires à l’échelle nationale puisque les paires sont comptées à deux endroits.
| Provinces et territoires | Paires sur la base | Paires dans l’échantillon |
|---|---|---|
| Canada | 1 029 616 | 3 658 |
| Terre-Neuve-et-Labrador | 52 174 | 640 |
| Île-du-Prince-Édouard | 15 546 | 561 |
| Nouvelle-Écosse | 93 331 | 695 |
| Nouveau-Brunswick | 77 998 | 650 |
| Québec | 316 352 | 490 |
| Ontario | 670 953 | 580 |
| Manitoba | 99 259 | 665 |
| Saskatchewan | 83 571 | 655 |
| Alberta | 293 933 | 495 |
| Colombie-Britannique | 348 355 | 500 |
| Yukon | 3 070 | 466 |
| Territoires du Nord-Ouest | 3 147 | 513 |
| Nunavut | 1 543 | 406 |
| Source : Statistique Canada, Étude sur le surdénombrement du Recensement de 2016. | ||
8.3.4 Échantillon de la strate 3
La strate 3 était composée de groupes et de voisinages interprovinciaux. Comme mentionné précédemment, un grand nombre de ces unités d’échantillonnage contiennent tout de même des paires intraprovinciales. Le défi était donc de réussir à sélectionner suffisamment de paires intraprovinciales, surtout pour les petites provinces et les territoires, sans causer la sélection d’un trop grand nombre de paires interprovinciales ou de paires d’unités dans les grandes provinces. Pour ce faire, les unités de la strate 3 ont été divisées de la façon suivante à l’aide de règles de dominance basées sur la proportion de paires intraprovinciales appartenant à une même province à l’intérieur des groupes et voisinages interprovinciaux :
- Les unités où au moins 60 % des paires étaient des paires intraprovinciales d’une province donnée;
- Les unités où entre 50 % et 60 % des paires étaient des paires intraprovinciales d’une province donnée;
- Les unités où moins de 50 % des paires appartenaient à la même province.
Une simulation a été effectuée pour déterminer la taille d’échantillon requise dans chaque sous-strate afin d’obtenir les tailles d’échantillon visées pour le nombre de paires intraprovinciales et interprovinciales dans chaque province. Un échantillon aléatoire simple de groupes et voisinages a ensuite été sélectionné dans chaque sous-strate. Le tableau 8.3.4 présente, pour chaque sous-strate, la règle de dominance appliquée (proportion et province la plus fréquente), le nombre d’unités d’échantillonnage (groupes et voisinages) dans la sous-strate, le nombre de paires composant ces unités ainsi que le nombre d’unités échantillonnées.
Les sous-strates 1 à 11 étaient formées des unités d’échantillonnage où au moins 60 % des paires intraprovinciales se trouvaient dans une même province ou un même territoire (il n’y en avait pas au Yukon ni au Nunavut). Les sous-strates 13 à 16 étaient formées des unités composées de paires interprovinciales seulement, et où la province ou le territoire le plus fréquent parmi tous les enregistrements de la BDR-ECR dans l’unité était respectivement l’Île-du-Prince-Édouard (9911), le Yukon (9960), les Territoires du Nord-Ouest (9961) ou le Nunavut (9962). La sous-strate 12 contenait toutes les autres unités composées de paires interprovinciales seulement. Les sous-strates 17 à 29 étaient composées des unités où au moins 50 %, mais moins de 60 % des paires intraprovinciales provenaient d’une province donnée. Finalement, les sous-strates 30 à 42 comprenaient toutes les autres unités d’échantillonnage, classées selon la province la plus fréquente parmi toutes les paires intraprovinciales. Par exemple, la sous-strate 23 était composée de toutes les unités d’échantillonnage où au moins 50 %, mais moins de 60 % des paires intraprovinciales provenaient du Manitoba.
| Sous-strate | Province ou territoire | Nombre d’unités d’échantillonnage sur la base | Nombre de paires dans les unités d’échantillonnage | Nombre d’unités échantillonnées |
|---|---|---|---|---|
| Total | Canada | 997 209 | 3 113 046 | 3 766 |
| 60 % ou plus | ||||
| 1 | 10 | 98 | 374 | 98 |
| 2 | 11 | 16 | 56 | 16 |
| 3 | 12 | 261 | 982 | 168 |
| 4 | 13 | 234 | 1 008 | 139 |
| 5 | 24 | 35 259 | 157 968 | 237 |
| 6 | 35 | 56 977 | 250 169 | 236 |
| 7 | 46 | 208 | 837 | 148 |
| 8 | 47 | 168 | 762 | 117 |
| 9 | 48 | 2 108 | 8 465 | 185 |
| 10 | 59 | 8 986 | 37 667 | 214 |
| 11 | 61 | 1 | 3 | 1 |
| 12 | 9900 | 424 804 | 971 198 | 275 |
| 13 | 9911 | 10 664 | 28 813 | 81 |
| 14 | 9960 | 1 974 | 5 310 | 81 |
| 15 | 9961 | 1 988 | 5 329 | 81 |
| 16 | 9962 | 681 | 1 911 | 81 |
| Au moins 50 % mais moins de 60 % | ||||
| 17 | 10 | 1 057 | 2 314 | 152 |
| 18 | 11 | 174 | 381 | 102 |
| 19 | 12 | 2 175 | 4 773 | 60 |
| 20 | 13 | 1 614 | 3 667 | 60 |
| 21 | 24 | 44 438 | 114 348 | 78 |
| 22 | 35 | 112 607 | 301 663 | 97 |
| 23 | 46 | 1 731 | 3 790 | 95 |
| 24 | 47 | 1 262 | 2 784 | 95 |
| 25 | 48 | 12 287 | 28 069 | 129 |
| 26 | 59 | 27 016 | 69 808 | 119 |
| 27 | 60 | 22 | 44 | 22 |
| 28 | 61 | 8 | 16 | 8 |
| 29 | 62 | 5 | 10 | 5 |
| Moins de 50 % | ||||
| 30 | 10 | 2 335 | 9 959 | 64 |
| 31 | 11 | 378 | 1 544 | 75 |
| 32 | 12 | 4 461 | 18 969 | 44 |
| 33 | 13 | 3 783 | 15 606 | 44 |
| 34 | 24 | 38 148 | 162 831 | 30 |
| 35 | 35 | 96 087 | 422 284 | 30 |
| 36 | 46 | 3 903 | 17 103 | 44 |
| 37 | 47 | 3 089 | 13 033 | 44 |
| 38 | 48 | 22 495 | 101 325 | 30 |
| 39 | 59 | 73 556 | 347 254 | 30 |
| 40 | 60 | 80 | 322 | 80 |
| 41 | 61 | 55 | 230 | 55 |
| 42 | 62 | 16 | 67 | 16 |
| Source : Statistique Canada, Étude sur le surdénombrement du Recensement de 2016. | ||||
8.3.5 Échantillon de la strate 4
La strate 4 contenait toutes les paires d’enregistrements déterminées à l’aide du supplément. Comme la strate 4 a été ajoutée après la création des groupes et des voisinages formés par les paires interconnectées des étapes 1 à 3, toutes les unités d’échantillonnage de la strate 4 ont été traitées comme des paires. Cette strate a été sous-stratifiée selon la province. Une répartition de puissance a permis de répartir l’échantillon de 3 000 paires entre les provinces et territoires. De plus, une répartition optimale, basée sur les taux de surdénombrement attendus, a permis de répartir l’échantillon d’une province entre les paires intraprovinciales et interprovinciales. Un échantillon systématique de paires de la BDR a ensuite été choisi dans chaque sous-strate. Le tableau 8.3.5 présente, pour chaque province et territoire, le nombre de paires intraprovinciales et interprovinciales totales figurant dans la base, de même que le nombre de paires échantillonnées. Encore une fois, dans le cas des paires interprovinciales, il est important de noter que le total à l’échelle nationale correspond à la moitié de la somme des nombres de chaque province et territoire, puisque chaque paire interprovinciale est comptée au total dans deux provinces.
| Provinces et territoires | Paires sur la base | Paires dans l’échantillon | ||
|---|---|---|---|---|
| Intraprovinciales | Interprovinciales | Intraprovinciales | Interprovinciales | |
| Canada | 74 987 | 22 099 | 2 520 | 548 |
| Terre-Neuve-et-Labrador | 967 | 935 | 144 | 70 |
| Île-du-Prince-Édouard | 221 | 314 | 87 | 61 |
| Nouvelle-Écosse | 1 608 | 1 836 | 163 | 93 |
| Nouveau-Brunswick | 1 314 | 1 377 | 156 | 81 |
| Québec | 15 803 | 5 922 | 367 | 95 |
| Ontario | 31 264 | 13 927 | 444 | 128 |
| Manitoba | 2 109 | 2 427 | 177 | 101 |
| Saskatchewan | 1 886 | 2 192 | 170 | 99 |
| Alberta | 7 831 | 6 982 | 272 | 122 |
| Colombie-Britannique | 11 763 | 7 979 | 319 | 116 |
| Yukon | 78 | 81 | 78 | 34 |
| Territoires du Nord-Ouest | 56 | 113 | 56 | 53 |
| Nunavut | 87 | 113 | 87 | 43 |
| Source : Statistique Canada, Étude sur le surdénombrement du Recensement de 2016. | ||||
8.4 Collecte
Le processus de collecte consistait en une vérification manuelle des échantillons de groupes de paires sélectionnés, vérification qui se faisait paire par paire. Lorsqu’un groupe ou un voisinage était échantillonné, toutes les paires qui le constituaient étaient examinées manuellement. Les paires n’étaient examinées qu’une fois, même si elles appartenaient à plus d’un voisinage échantillonné.
Le processus de vérification manuelle consistait en un examen exhaustif de l’ensemble des renseignements disponible sur la BDR-ECR. Comme en 2011, il comprenait les étapes suivantes :
- Comparaison des personnes échantillonnées de la BDR-ECR selon le nom, le sexe, la date de naissance ainsi que les liens entre les personnes;
- Comparaison des membres des ménages figurant dans la BDR-ECR selon les mêmes critères;
- Évaluation des preuves pour ou contre le surdénombrement entre les deux personnes de la paire, c’est-à-dire déterminer si les deux enregistrements représentent effectivement la même personne;
- Détermination du scénario de surdénombrement, codé seulement lorsqu’il y a surdénombrement vérifié entre des ménages non identiques. Les scénarios de surdénombrement sont fournis dans le tableau 8.4.
| Code | Scénario de surdénombrement entre ménages non identiques |
|---|---|
| 1.1 | Étudiant ou jeune adulte ayant récemment quitté le domicile familial |
| 1.2 | Jeune adulte récemment sorti du domicile familial en raison d’une relation conjugale ou d’une union libre |
| 1.3 | Adulte ayant récemment entamé une relation conjugale ou une union libre, ou ayant récemment rompu une telle relation ou union |
| 2.1 | Un ou des enfants de parents dans des ménages séparés |
| 2.2 | Un ou des enfants avec deux membres de la famille ou deux adultes |
| 3.1 | Adulte avec d’autres membres de la famille |
| 3.2 | Adulte avec d’autres adultes non apparentés |
| 4.1 | Ménage collectif |
| 5.1 | Autre |
| Source : Statistique Canada, Étude sur le surdénombrement du Recensement de 2016. | |
L’échantillon de la vérification manuelle était divisé en lots de 150 paires. Un lot était vérifié en entier par le même codeur. Une fois la vérification d’un lot terminée, celui-ci était évalué à l’aide d’une opération de contrôle statistique de la qualité.
8.5 Pondération et estimation
Le poids de départ d’une unité d’échantillonnage était simplement l’inverse de sa probabilité de sélection. Étant donné que les unités d’échantillonnage qui étaient des groupes ou des voisinages variaient en ce qui concerne le nombre de paires qu’elles contenaient, une étape de calage a été ajoutée afin d’assurer une bonne représentation du nombre de paires dans chaque province et territoire. Dans la strate 1 (unités intraprovinciales), les poids d’échantillonnage ont été calés de façon à ce que le nombre estimé de paires corresponde au nombre total de paires dans la base pour chaque province et territoire. Dans la strate 3 (groupes et voisinages interprovinciaux), les poids de sondage ont été calés de façon à ce que le nombre estimé de paires intraprovinciales et interprovinciales dans chaque province ou territoire soit égal au total correspondant de la base. Ainsi, 13 totaux de contrôle ont été utilisés pour la strate 1 comparativement à 26 pour la strate 3. Le Système généralisé d’estimation (G-Est) de Statistique Canada a servi à effectuer le calage. Aucun calage n’était requis pour les strates 2 et 4, puisqu’elles ne contenaient que des paires. Le tableau 8.5a présente les trois facteurs de calage pour chaque province et territoire.
| Provinces et territoires | Strate 1 | Strate 3 | |
|---|---|---|---|
| Intraprovinciales | Interprovinciales | ||
| Terre-Neuve-et-Labrador | 1,003 | 1,049 | 0,899 |
| Île-du-Prince-Édouard | 1,000 | 1,057 | 1,136 |
| Nouvelle-Écosse | 0,998 | 1,071 | 0,945 |
| Nouveau-Brunswick | 0,996 | 0,901 | 1,225 |
| Québec | 1,013 | 0,988 | 0,942 |
| Ontario | 1,014 | 1,001 | 1,008 |
| Manitoba | 1,008 | 1,013 | 1,117 |
| Saskatchewan | 1,007 | 1,041 | 0,962 |
| Alberta | 1,000 | 0,971 | 0,997 |
| Colombie-Britannique | 0,999 | 0,956 | 0,951 |
| Yukon | 1,000 | 1,039 | 1,415 |
| Territoires du Nord-Ouest | 1,000 | 1,015 | 1,468 |
| Nunavut | 1,000 | 1,000 | 0,493 |
| Source : Statistique Canada, Étude sur le surdénombrement du Recensement de 2016. | |||
Les résultats de la vérification manuelle ont été traités afin de créer des groupes de surdénombrement servant à l’estimation. Les groupes de surdénombrement étaient formés de tous les enregistrements BDR reliés par du surdénombrement vérifié. Les estimations de l’ESR ont été obtenues en sommant le surdénombrement estimé compté dans chaque groupe de surdénombrement. Pour un groupe de surdénombrement qui était une simple paire, le compte du surdénombrement était de 1. Si le groupe de surdénombrement était contenu dans un petit groupe d’enregistrements (c.-à-d. un groupe n’ayant pas été brisé en voisinages), alors la formule suivante s’appliquait :
Surdénombrement = nombre d’enregistrements dans le groupe de surdénombrement - 1.
Pour les groupes de surdénombrement brisés en voisinages, le surdénombrement était compté en suivant les deux étapes suivantes :
- Calculer le surdénombrement dans chaque voisinage dont l’ancrage (c.-à-d. l’enregistrement BDR-ECR tenant lieu de centre du voisinage) était impliqué dans des cas de surdénombrement vérifiés pour ce groupe de surdénombrement, de la façon suivante :
- SD dans le voisinage =
- Additionner le surdénombrement de chaque voisinage pour obtenir le surdénombrement total du groupe.
Le surdénombrement pour un domaine était obtenu en multipliant le surdénombrement total de la paire, du groupe ou du voisinage par la proportion d’enregistrements BDR-ECR faisant partie du domaine parmi ceux appartenant au groupe de surdénombrement.
Dans tous les cas décrits ci-dessus, le surdénombrement calculé pour une unité était multiplié par le poids après calage de l’unité d’échantillonnage pour obtenir l’estimation pondérée. La variance a été estimée à l’aide de G-Est, qui utilise la linéarisation de Taylor.
De manière semblable à ce qui avait été fait dans l’ESR de 2006 et de 2011, un ajustement basé sur l’EAA a été appliqué aux estimations de l’ESR pour tenir compte du surdénombrement mesuré par l’EAA en dehors de l’univers de l’ESR. Le facteur d’ajustement a été calculé et appliqué séparément pour chaque province et territoire. La variance finale tenait compte de cet ajustement. Le tableau 8.5b montre le facteur d’ajustement appliqué pour chaque province et territoire, pour les trois derniers cycles de l’ESR.
| Provinces et territoires | 2006 | 2011 | 2016 |
|---|---|---|---|
| Terre-Neuve-et-Labrador | 1,029 | 1,030 | 1,035 |
| Île-du-Prince-Édouard | 1,028 | 1,017 | 1,003 |
| Nouvelle-Écosse | 1,034 | 1,021 | 1,012 |
| Nouveau-Brunswick | 1,040 | 1,071 | 1,037 |
| Québec | 1,026 | 1,016 | 1,008 |
| Ontario | 1,040 | 1,020 | 1,015 |
| Manitoba | 1,035 | 1,025 | 1,010 |
| Saskatchewan | 1,039 | 1,010 | 1,006 |
| Alberta | 1,058 | 1,018 | 1,026 |
| Colombie-Britannique | 1,037 | 1,017 | 1,029 |
| Yukon | 1,027 | 1,014 | 1,010 |
| Territoires du Nord-Ouest | 1,039 | 1,169 | 1,015 |
| Nunavut | 1,061 | 1,015 | 1,023 |
|
EAA : Étude par appariement automatisé. ESR : Étude sur le surdénombrement du recensement. Sources : Statistique Canada, Étude sur le surdénombrement du recensement de 2006, 2011 et 2016. |
|||
8.6 Résultats finaux
8.6.1 Surdénombrement par étape
La contribution de chacune des étapes aux estimations du surdénombrement de l’ESR de 2016 ainsi que celle de l’ajustement par l’EAA est fournie dans le tableau 8.6.1.
| Provinces et territoires | Étape 1 | Étape 2 | Étape 3 | Étape 4 | Ajustement par l'EAA | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Nombre estimé | Pourcentage du total | Nombre estimé | Pourcentage du total | Nombre estimé | Pourcentage du total | Nombre estimé | Pourcentage du total | Nombre estimé | Pourcentage du total | |
| Canada | 602 995 | 85,25 | 1 759 | 0,25 | 36 229 | 5,12 | 54 845 | 7,75 | 11 508 | 1,63 |
| Terre-Neuve-et-Labrador | 9 345 | 84,38 | 47 | 0,42 | 486 | 4,39 | 823 | 7,43 | 374 | 3,38 |
| Île-du-Prince-Édouard | 2 082 | 86,35 | 9 | 0,37 | 98 | 4,06 | 214 | 8,88 | 8 | 0,33 |
| Nouvelle-Écosse | 14 375 | 84,25 | 105 | 0,62 | 788 | 4,62 | 1 599 | 9,37 | 196 | 1,15 |
| Nouveau-Brunswick | 14 334 | 86,10 | 42 | 0,25 | 591 | 3,55 | 1 095 | 6,58 | 586 | 3,52 |
| Québec | 159 996 | 90,97 | 367 | 0,21 | 5 619 | 3,19 | 8 519 | 4,84 | 1 385 | 0,79 |
| Ontario | 217 852 | 84,02 | 362 | 0,14 | 14 591 | 5,63 | 22 759 | 8,78 | 3 724 | 1,44 |
| Manitoba | 16 975 | 85,53 | 60 | 0,30 | 1 032 | 5,20 | 1 585 | 7,99 | 195 | 0,98 |
| Saskatchewan | 17 235 | 79,60 | 82 | 0,38 | 2 626 | 12,13 | 1 586 | 7,33 | 122 | 0,56 |
| Alberta | 60 144 | 82,69 | 253 | 0,35 | 3 853 | 5,30 | 6 637 | 9,12 | 1 851 | 2,54 |
| Colombie-Britannique | 89 000 | 81,89 | 418 | 0,38 | 6 395 | 5,88 | 9 833 | 9,05 | 3 036 | 2,79 |
| Yukon | 692 | 81,51 | 6 | 0,71 | 59 | 6,95 | 84 | 9,89 | 8 | 0,94 |
| Territoires du Nord-Ouest | 467 | 83,24 | 4 | 0,71 | 26 | 4,63 | 56 | 9,98 | 8 | 1,43 |
| Nunavut | 497 | 78,02 | 4 | 0,63 | 65 | 10,20 | 57 | 8,95 | 14 | 2,20 |
|
EAA : Étude par appariement automatisé. Source : Statistique Canada, Étude sur le surdénombrement du Recensement de 2016. |
||||||||||
Environ 85 % du surdénombrement a été estimé à partir des doublons possibles identifiés à l’étape 1. En raison de l’élargissement de la partie de la base provenant de l’étape 1 (couplage de la BDR-ECR à elle-même), le repérage de doublons possibles de la BDR par le couplage à un fichier administratif intermédiaire (étape 2) n’a pas beaucoup contribué à l’estimation globale du surdénombrement du recensement. Il convient de rappeler que les doublons potentiels identifiés à la fois à l’étape 1 et à l’étape 2 étaient compris dans la liste de l’étape 1. L’extension (étape 3) a fait en sorte d’ajouter 36 229 personnes au surdénombrement estimé. Cela représente 6,0 % des cas repérés aux étapes 1 et 2 combinées, ce qui est conforme au résultat observé en 2011, où l’extension représentait 5,4 % de l’estimation totale aux étapes 1 et 2. Le supplément (étape 4) a donné lieu au repérage de 54 845 personnes surdénombrées. Cela représente 56,5 % des 97 086 paires ajoutées à la base de sondage de l’ESR par le supplément. Cette proportion est très élevée, mais elle était à prévoir étant donné que l’objectif du supplément était d’ajouter des paires qui ont été signalées comme de possibles doublons de la BDR, mais qui ont été omises aux étapes 1 à 3. L’ajustement par l’EAA a ajouté 11 508 personnes à l’estimation du surdénombrement, ce qui représente 1,6 % de l’estimation finale.
La contribution de l’étape 1 à l’estimation provinciale ou territoriale totale était moindre pour le Nunavut (78,0 %) et la Saskatchewan (79,6 %), où la contribution provenant de l’extension était plus élevée qu’ailleurs. En revanche, la contribution de l’étape 1 était plus élevée pour le Québec (91,0 %), où les contributions provenant de l’extension et du supplément étaient les plus faibles parmi tous les secteurs de compétence.
8.6.2 Répartition du surdénombrement par scénario
Les résultats du surdénombrement par scénario sont présentés dans le tableau 8.6.2, les codes de scénario de surdénombrement ayant déjà été présentés à la section 8.4. Rappelons que le scénario de surdénombrement est codé seulement lorsqu’il y a surdénombrement entre des ménages non identiques.
| Provinces et territoires | Scénario de surdénombrement | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1.1 | 1.2 | 1.3 | 2.1 | 2.2 | 3.1 | 3.2 | 4.1 | 5.1 | |
| Étudiant ou jeune adulte ayant récemment quitté le domicile familial | Jeune adulte récemment sorti du domicile familial en raison d’une relation conjugale ou d’une union libre | Adulte ayant récemment entamé une relation conjugale ou une union libre, ou ayant récemment rompu une telle relation ou union | Un ou des enfants de parents dans des ménages séparés | Un ou des enfants avec deux membres de la famille ou deux adultes | Adulte avec d’autres membres de la famille | Adulte avec d’autres adultes non apparentés | Ménage collectif | Autre | |
| pourcentage | |||||||||
| Canada | 18,8 | 4,3 | 3,8 | 42,4 | 3,9 | 10,1 | 4,0 | 8,1 | 4,6 |
| Terre-Neuve-et-Labrador | 26,8 | 3,6 | 5,5 | 39,4 | 6,0 | 5,9 | 3,6 | 4,8 | 4,4 |
| Île-du-Prince-Édouard | 25,2 | 3,7 | 2,8 | 48,4 | 5,9 | 4,1 | 2,8 | 4,4 | 2,7 |
| Nouvelle-Écosse | 25,3 | 5,3 | 4,2 | 42,8 | 3,1 | 4,3 | 2,0 | 7,5 | 5,5 |
| Nouveau-Brunswick | 24,0 | 4,7 | 4,9 | 37,8 | 5,7 | 6,7 | 1,8 | 9,2 | 5,2 |
| Québec | 14,8 | 7,1 | 1,9 | 56,0 | 1,7 | 3,9 | 2,5 | 8,2 | 3,9 |
| Ontario | 22,1 | 3,3 | 5,1 | 33,1 | 5,3 | 15,8 | 3,8 | 7,0 | 4,4 |
| Manitoba | 16,9 | 2,6 | 5,1 | 40,8 | 5,4 | 8,8 | 3,7 | 12,6 | 4,2 |
| Saskatchewan | 16,5 | 0,8 | 4,6 | 51,1 | 5,4 | 5,8 | 3,4 | 9,0 | 3,3 |
| Alberta | 17,8 | 3,2 | 2,7 | 39,8 | 5,0 | 13,6 | 7,0 | 6,5 | 4,4 |
| Colombie-Britannique | 17,5 | 1,6 | 5,3 | 36,1 | 2,5 | 9,7 | 7,5 | 12,0 | 7,8 |
| Yukon | 10,3 | 1,9 | 2,5 | 42,4 | 4,5 | 16,0 | 3,2 | 6,9 | 12,2 |
| Territoires du Nord-Ouest | 14,0 | 5,2 | 2,9 | 28,7 | 9,2 | 11,6 | 6,3 | 7,2 | 14,9 |
| Nunavut | 9,0 | 6,9 | 7,3 | 16,8 | 22,8 | 17,0 | 2,9 | 6,4 | 11,0 |
| Source : Statistique Canada, Étude sur le surdénombrement du Recensement de 2016. | |||||||||
Comme ce fut le cas en 2011, le scénario « Un ou des enfants de parents dans des ménages séparés », où des parents séparés ou divorcés inscrivent tous deux leurs enfants dans leur questionnaire respectif du recensement, est celui qui a été observé le plus souvent. C’est le cas dans chaque province et territoire, sauf au Nunavut. La catégorie « Autre » a été utilisée moins souvent en 2016 que cinq ans auparavant. En 2011, il s’agissait même du scénario le plus fréquent au Nunavut et en Colombie-Britannique. En 2016, la Colombie-Britannique affichait toujours la plus forte proportion de cas de scénario « Autre » parmi les dix provinces, mais elle représentait le tiers du taux enregistré en 2011.
À l’échelle nationale, les deux autres scénarios les plus fréquents demeuraient « Étudiant ou jeune adulte ayant récemment quitté le domicile familial » et « Adulte avec d’autres membres de la famille ». Il y a eu davantage de cas de surdénombrement entre un logement privé et un ménage collectif (scénario 4.1) en 2016 qu’en 2011 (8,1 % comparativement à 2,5 %). En 2016, l’extension a également été appliquée à la comparaison des ménages où un membre compris dans une paire repérée à l’étape 1 ou 2 vivait dans un logement privé et où l’autre membre vivait dans un ménage collectif, alors qu’en 2011, l’extension se limitait à la comparaison des logements privés; ce changement n’explique toutefois qu’une toute petite portion de l’augmentation. Beaucoup de ces cas observés en 2011 ont fort possiblement été codés dans la catégorie « Autre », mais la confirmation de cette hypothèse demanderait de retourner aux données de la vérification manuelle de l’ESR de 2011, ce qui n’a pas été fait. Le même raisonnement pourrait être appliqué à la proportion d’enfants de parents dans des ménages séparés : il n’y a pas eu d’augmentation si forte du nombre de parents séparés entre 2011 et 2016; des investigations supplémentaires seraient dès lors requises afin de déterminer la portion de ce changement qui résulte du codage comparativement à celle qui émane d’un véritable changement dans le comportement des parents séparés quant au dénombrement de leurs enfants.
Notes
- Date de modification :